Inhaltsverzeichnis
ToggleWie funktioniert Stable Diffusion in Kürze:
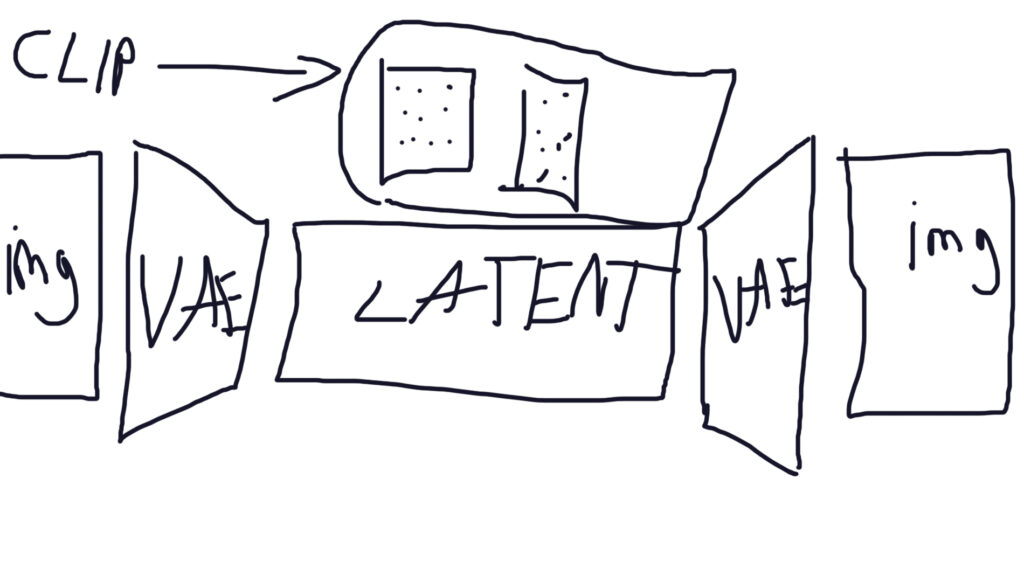
Das Bildgenerierungsverfahren in Stable Diffusion beginnt damit, eine verrauschte Version des Zielbildes in eine komprimierte Darstellung namens Latenter Raum zu codieren. (ComfyUI: VAE Encode Node)
Anschließend entrauscht ein U-Net-Modell iterativ diese latente Darstellung. In jedem Schritt sagt das U-Net das zu entfernende Rauschen vorher, während ein separater Textencoder (wie CLIP) basierend auf der Textbeschreibung Anleitung gibt. (ComfyUI: Sampler Node)
Schließlich wird die entrauschte latente Darstellung zurück in ein Bild im Pixelraum decodiert. (ComfyUI: VAE Decoder Node)
Stable Diffusion ist ein leistungsstarkes Tool, das Künstler und Designer verwenden, um atemberaubende AI-generierte Bilder aus Text zu erstellen. Aber wie funktioniert es wirklich? In diesem Artikel werden wir uns ausführlich mit der Funktionsweise von Stable Diffusion befassen und Ihnen ein grundlegendes Verständnis seiner inneren Mechanismen vermitteln.
Was ist Stable Diffusion?
Stable Diffusion ist ein latentes Diffusionsmodell, das AI-Bilder aus Text generiert. Es arbeitet im Latentraum, einem niedrigdimensionalen Raum, in den das Bild zunächst komprimiert wird. Anstatt im hochdimensionalen Bildraum zu arbeiten, generiert Stable Diffusion ein AI-Bild, das dem Text-Prompt entspricht, indem es im Latentraum arbeitet.
Wie wird das Training durchgeführt?
Um die Diffusion rückgängig zu machen, müssen wir wissen, wie viel Rauschen einem Bild hinzugefügt wurde. Dazu wird ein neuronales Netzwerkmodell trainiert, um das Rauschen vorherzusagen. Dies geschieht durch Abstimmen seiner Gewichte und Zeigen der korrekten Antwort. Sobald wir den Rauschvorhersager haben, generieren wir ein völlig zufälliges Bild und fragen den Rauschvorhersager, welches Rauschen vorliegt. Dann subtrahieren wir dieses geschätzte Rauschen schrittweise vom Originalbild.
Was ist Reverse Diffusion?
Reverse Diffusion ist der Prozess, bei dem ein zufälliges Rauschbild schrittweise in ein AI-generiertes Bild umgewandelt wird, das dem Text-Prompt entspricht. Dies geschieht, indem das geschätzte Rauschen vom Originalbild subtrahiert wird, um das AI-generierte Bild zu erhalten.
Was ist ein Variational Autoencoder (VAE)?
Ein Variational Autoencoder (VAE) ist ein neuronales Netzwerk, das ein Bild in eine niedrigdimensionale Darstellung im Latentraum komprimiert und dann das Bild aus dem Latentraum wiederherstellt. Der VAE hat zwei Teile: einen Encoder, der das Bild komprimiert, und einen Decoder, der das Bild aus dem Latentraum wiederherstellt.
Wie funktioniert Stable Diffusion im Latentraum?
Stable Diffusion arbeitet im Latentraum, anstatt im hochdimensionalen Bildraum zu arbeiten. Dies hat den Vorteil, dass viel weniger Zahlen verarbeitet werden müssen, was den Prozess schneller und effizienter macht. Stable Diffusion verwendet einen VAE, um das Bild in den Latentraum zu komprimieren. Dann generiert es ein zufälliges Rauschbild im Latentraum und subtrahiert schrittweise das geschätzte Rauschen, um das AI-generierte Bild zu erhalten.
Was ist die CFG-Skala?
Die CFG-Skala ist ein Wert, der steuert, wie sehr der Text-Prompt den Diffusionsprozess steuert. Ein höherer CFG-Wert führt zu einer stärkeren Steuerung durch den Text-Prompt, was zu einem genaueren Ergebnis führt.
Fazit:
Stable Diffusion ist ein leistungsstarkes Tool, das Künstler und Designer verwenden, um atemberaubende AI-generierte Bilder aus Text zu erstellen. Mit einem grundlegenden Verständnis seiner inneren Mechanismen kannst du es effektiv nutzen, um Ihre Kreativität zu steigern und beeindruckende Ergebnisse zu erzielen. Indem du die Funktionsweise von Stable Diffusion verstehst, kannst du auch fundierte Entscheidungen darüber treffen, wie du es in deinen kreativen Projekten einsetzen kannst.
Willkommen im neuen Zeitalter der Künstlichen Intelligenz! Bleib nicht zurück, sondern sei der Konkurrenz einen Schritt voraus. Investiere jetzt in deine Zukunft, indem du dich systematisch von einem Anfänger zum Profi in der Stable Diffusion Web UI von Automatic1111 entwickelst. Unser gut strukturierter Videokurs bietet dir eine einfache und verständliche Anleitung. Sieh genau, wie es gemacht wird, und lerne durch praktische Übungen jeden Schritt nachzuvollziehen. Auf diese Weise wirst du Schritt für Schritt zum Experten in der Stable Diffusion Web UI von Automatic1111. Zum Stable Diffusion Automatic1111 WebUI Kurs.
Stable Diffusion arbeitet im Latentraum, anstatt im hochdimensionalen Bildraum zu arbeiten. Dies macht den Prozess schneller und effizienter.
Du kannst Stable Diffusion verwenden, um AI-generierte Bilder aus Text zu erstellen und diese als Inspiration für Ihre kreativen Projekte zu nutzen.
Ja, Stable Diffusion kann auch verwendet werden, um Bilder aus anderen Quellen als Text zu generieren, wie z.B. aus Tiefenkarten (depth maps (engl.)) oder anderen Bildern.
Du kannst die Genauigkeit deiner AI-generierten Bilder verbessern, indem Sie einen höheren CFG-Wert verwenden, was zu einer stärkeren Steuerung durch den Text-Prompt führt.
Du kannst Stable Diffusion in Ihren kreativen Projekten einsetzen, indem Sie AI-generierte Bilder als Ausgangspunkt für Ihre Designs verwenden oder indem Sie sie als Inspiration für Ihre künstlerischen Werke nutzen.